Last update: 2024 05 24
Like all R packages, groundhog is open source so you can see how everything works looking at the posted R Code, but this page explains intuitively how groundhog achieves reproducibility.
For groundhog to work, for R to load the version of a package based on the date in the groundhog.library() command, it needs to
1) Identify the package version for that date.
2) Identify all dependencies of the package on that date, and their versions.
3) Obtain all those package-versions, and save them in the user’s computer.
4) Load/attach the specified versions of packages into the R environment being used.
This document explains how each of these necessary steps are achieved.
1) Find the package version that matches the date in groundhog.library(pkg, date)
groundhog relies on a database that contains virtually all package versions ever uploaded to CRAN, the date when they were published, and all dependencies. Here are a few rows of that file (updated daily, and available here: http://groundhogR.com/cran.toc.rds). When a user enters the date they want a package for, a local copy of this table is consulted finding the most recently published version of the package for that date.
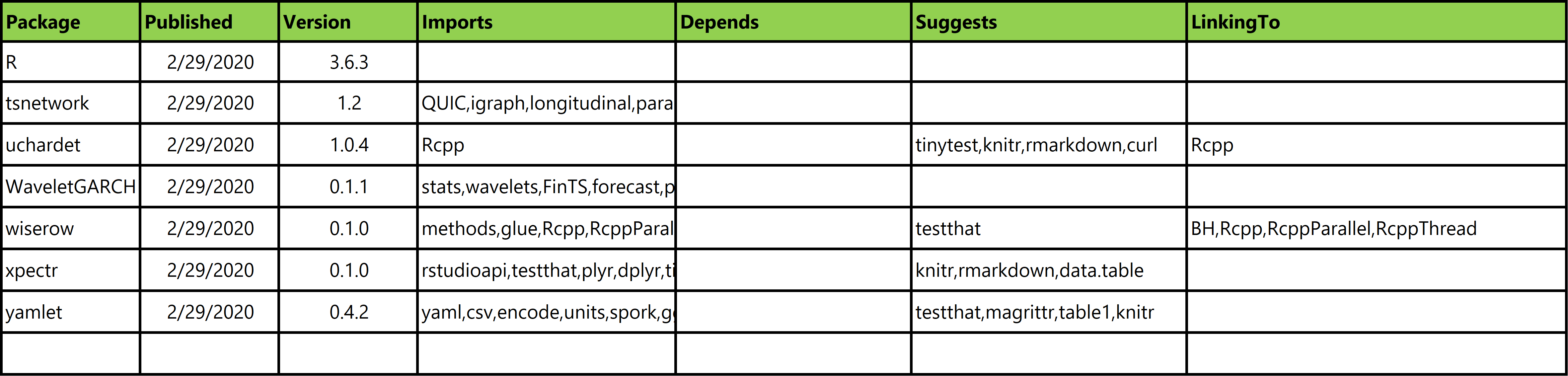
Details on how this database was created The database was created in three steps. First, an R script read the DESCRIPTION file for every package in the CRAN archives, obtaining dependencies and Published dates for all of them. But, it turns out that hundreds of Published dates are incorrect in those DESCRIPTION files. For example the DESCRIPTION for
MASS_7.3-45 indicates it was published on 2016-04-21, but it was actually published six months earlier, in November of 2015. Therefore, the Published date was obtained by running the command available.packages() on the daily MRAN copy of CRAN, and using the first date on which the package appears as available, as the publication date (for packages pre-MRAN, the DESCRIPTION date is used. After the database was first created, in early 2020, it is updated daily with an R script in the groundhogR.com server that runs available.packages() on CRAN daily, adding any new packages to the database, with the Publish date for when they were first found.
2) Find all the dependencies
Using the same cran.toc.rds file, we see all dependencies for a given package version. The groundhog.library() command includes the function get.snowball() which runs a loop finding the dependencies for the dependencies and so on until no new dependencies are to be added, and they are then sorted into the ‘snowball’. First in the snowball are packages that depend on no other package (referred affectionately as ‘independencies’), and the very last package in the snowball list is the package called on by groundhog.library()
3) Obtain all those package-versions, and save them in the user’s computer
Snowball in hand, a loop checks if each package-version is installed locally in the computer, if not they are looked for online. First looking for a binary on CRAN, if not found, a binary on GRAN, if not found, source from CRAN. The packages are then downloaded and installed if needed.
4) Load the specified versions of packages into the R environment being used
Base R uses by default a single library to store user-installed packages, consisting of a folder with package names as subfolders (without indicating package version). Those subfolders contain only the latest installed version of the corresponding package, and the files are deleted and replaced when a package gets updated.
For example, here is a print-screen for the library folder for my R 3.6
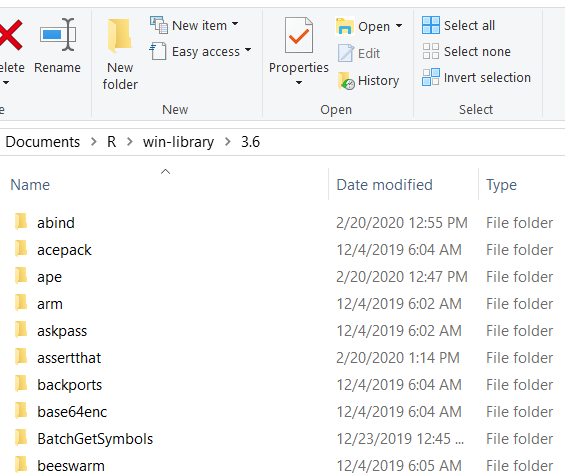
The folder “beeswarm” contains (some version of) the package with that name. If I run library('beeswarm') I would load it without controlling or easily knowing which version it is. If I run install.packages('beeswarm') I would replace it with whichever version is current, without documenting in any way that the package has been modified.
Groundhog uses a similar storage approach, but it enables version control. Specifically, and simply, each version of each package gets its own folder, for example, below we see two versions of jsonlite stored side by side in the groundhog folder.
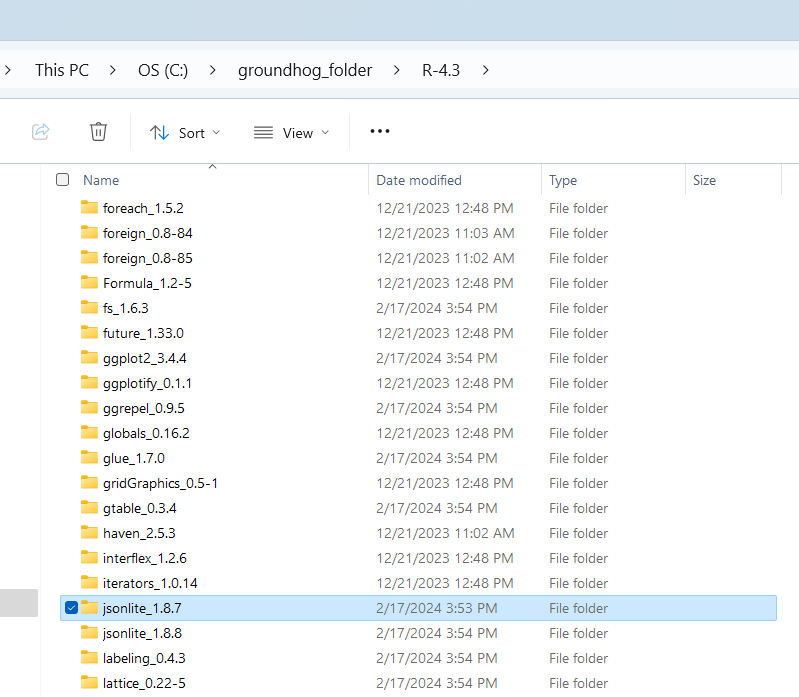
So, when running, say, groundhog.library("beeswarm","2016-01-02") the script identifies which version of the package is needed using cran.toc.rds, and checks whether that’s the version in the default library location in R (you can check that location in your computer by running .libPaths()[1]). If another version of the package is found, it is moved out of that folder and the correct version is moved in. groundhog.library() then loads and attaches the desired package from that location.
Groundhog essentially creates a library loan program, when you need a package you borrow it into your default R library from groundhog library, and when you request another version of that same package groundhog ‘returns’ it to the groundhog library, by moving the subfolder back. This is why you don’t have to re-install it, it just moves back and forth different locations in your computer. By moving folders, instead of copying them, the process is nearly instantaneous, because moving a folder is essentially just renaming it.
Groundhog includes a function, restore.library(), that will return the default library to its original contents prior to relying on groundhog.
Back-end prior to v3.0
Groundhog versions prior to 3.0 worked differently; they would not move packages into the default R library. But this smaller footprint solution from the original design became unworkable for two reasons. First, R Studio automatically loads R packages referenced in a script (from the default library location) and this created unresolvable package version conflicts (the package in that location would be immediately loaded, preventing the installation/loading of another version by groundhog). Second, for parallel processing R will by default look for packages in that location as well, and thus if packages are not moved there, when working with parallel processing (e.g., with foreach) the code would need to be customized to work well with groundhog. Now the exact same code will work whether you use groundhog.library() or library() to attach packages.